Introducing the Network Indexer

Protocol Labs recently launched the first production Network Indexer to enable searching for content-addressable data available from storage providers, such as those on the Filecoin and IPFS networks. Storage providers can now publish the content IDs (CIDs) of their data to the Network Indexer, and clients can query the Network Indexer to learn where to retrieve the content identified by those CIDs.
What is a Network Indexer
A Network Indexer (indexer for short) is a system that maps CIDs to records of who has the data (provider data records). It is built to handle the scale of data in the Filecoin network and is usable by the IPFS network for locating data.
Storage providers publish data to indexers, for clients to be able to find. A client that wants to know where a piece of information is stored can query an indexer, using the CID or multihash of the content. The indexer responds to the client with information about the provider(s). This tells where the client can retrieve the content from, and how the content can be retrieved. Below is an architecture diagram that describes the Network Indexing system:
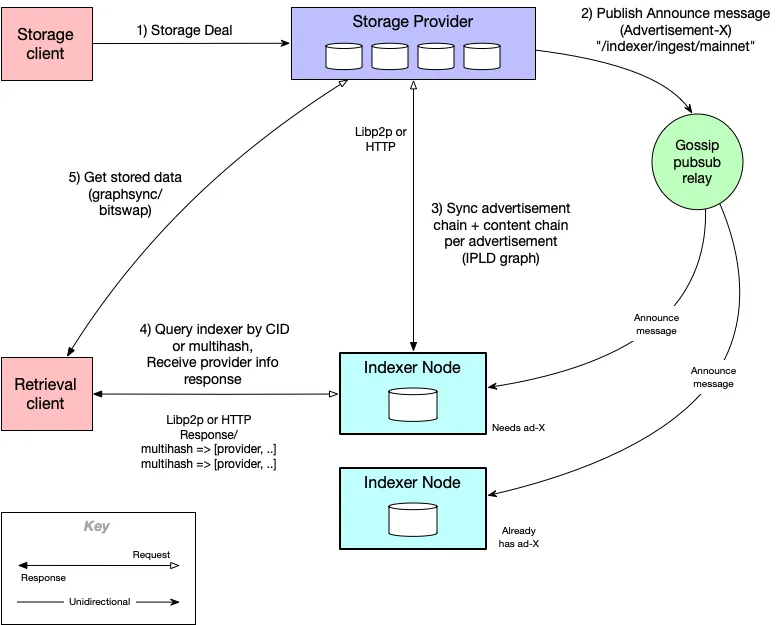
Current Indexer Status
The network indexer is operating at scale, handling over 11,000 queries per second, and has already indexed 6 billion CIDs. We expect these numbers will continue to grow, as more storage providers index more content.
How To Use A Network Indexer
A network indexer is hosted at cid.contact and can be accessed by sending requests to its API via HTTP or libp2p. The cid.contact indexer has a lightweight web interface that can be used to manually enter a CID and query the indexer. This makes a request to cid.contact/cid/ and displays the results.
Real World Example
Here is a demonstration of finding content using the cid.contact indexer:
Copy this CID bafybeigvgzoolc3drupxhlevdp2ugqcrbcsqfmcek2zxiw5wctk3xjpjwy into the cid.contact search box.
The indexer returns a response that indicated this CID is found at the storage provider with ID 12D3KooWDMJSprsuxhjJVnuQQcyibc5GxanUUxpDzHU74rhknqkU that has the address /ip4/89.20.96.58/tcp/24001. Now you can go ahead and retrieve the data!
An example retrieval client can be found in the w3rc github repo.
This same query can be performed directly using this URL to query by CID: https://cid.contact/cid/bafybeigvgzoolc3drupxhlevdp2ugqcrbcsqfmcek2zxiw5wctk3xjpjwy
This returns the provider information as JSON:
{
"MultihashResults": [
{
"Multihash": "EiDVNlzli2ONH3OslRv1Q0BRCKUCsERWs3RbthTVu6Xptg==",
"ProviderResults": [
{
"ContextID": "AXESIBD01Ud5R2aNm17hy5POqaKeNmIzfSNMhnAGzhvNCfK/",
"Metadata": "kBKjaFBpZWNlQ0lE2CpYKAABgeIDkiAg1bFuob1/knnbN6PTonjf6wUGeB/qc2hJb4oriOwRjTNsVmVyaWZpZWREZWFs9W1GYXN0UmV0cmlldmFs9Q==",
"Provider": {
"ID": "12D3KooWDMJSprsuxhjJVnuQQcyibc5GxanUUxpDzHU74rhknqkU",
"Addrs": ["/ip4/89.20.96.58/tcp/24001"]
}
}
]
}
]
}
This result also shows the CID is available from the provider with ID 12D3KooWBwUERBhJPtZ7hg5N3q1DesvJ67xx9RLdSaStBz9Y6Ny8 and is reachable at the address /dns4/yablufc.ddns.net/tcp/4567. The metadata field contains data that the provider uses to locate and deliver the content to a client.
Indexer query results may contain multiple provider records for a CID if the content identified by that CID is available by multiple providers. Batch querying is also available to lookup a number of CIDs in a single request. This is why the response contains an array of MultihashResults to support querying for multiple CIDs.
To look up provider information by multihash, instead of CID, use the cid.contact/multihash/ endpoint. To see a list of providers that the indexer has data from see the cid.contact/providers endpoint.
Can I run my own Network Indexer
Yes, you can run a network indexer to index your own content. The indexer can be built for most platforms using the code here: https://github.com/filecoin-project/storetheindex.
How to run and configure your own indexer will be a topic for future discussion. Technical resources about providing data to an indexer are linked below:
What’s Next
With the latest lotus release, Storage Providers will soon be indexing the majority of Filecoin content, and we’re excited to see the use cases that emerge from enabling content discovery via an interplanetary network index.
We plan to increase the resiliency of the network index by increasing the set of indexer nodes on the network. We encourage interested parties to run the software and reach out to the team at #storetheindex on Filecoin Slack to get involved.