Retrieving Memories from the FIL Dev Summit

During the Filecoin Developer Summit in Iceland, Filecoin and IPFS retrieval was a topic of significant interest and excitement. The retrieval track, along with a number of related critical discussions, helped align the community on what’s needed for reliable Filecoin retrievals.
Recap
There were two main focal points of conversation in the Filecoin Retrievals & Data Availability track. The first was the flywheel that’s developing for measuring and incentivizing retrievals - aiming to bring performant and reliable data retrieval to Filecoin. The second was a conversation about how to effectively structure data and transfer it efficiently across the network (transport protocols and data structuring).
How to measure and incentivize retrieval
{{< youtube id="tKTGSQ4-V3c" title="Retrieval Expectations" >}}
Concrete retrieval SLAs
The first goal was a clear understanding of what we need in retrieval. Multiple discussions described specific definitions of retrieval, which help to reduce uncertainty and allow for better retrieval measurement and optimization. In his talk Retrieval Requirements for Filecoin SPs, Jaun Benet defined retrieval types and shared his vision for how verified retrievals could be implemented on Filecoin.
{{< youtube id="https://www.youtube.com/watch?v=pxGyzTZQU5U&list=PL_0VrY55uV1_YBBxt5rCooKSpSK4twObN&index=2" title="Defining Filecoin Retrievability" >}}
The underlying costs of retrieval were also discussed in terms of bandwidth and operational overhead - with an emerging expectation to define a level of minimum reserved bandwidth bundled with each storage deal. This definition translates into much clearer cost, and allows retrieval providers to better charge and understand what is expected by their clients in terms of data retrieval performance and bandwidth.
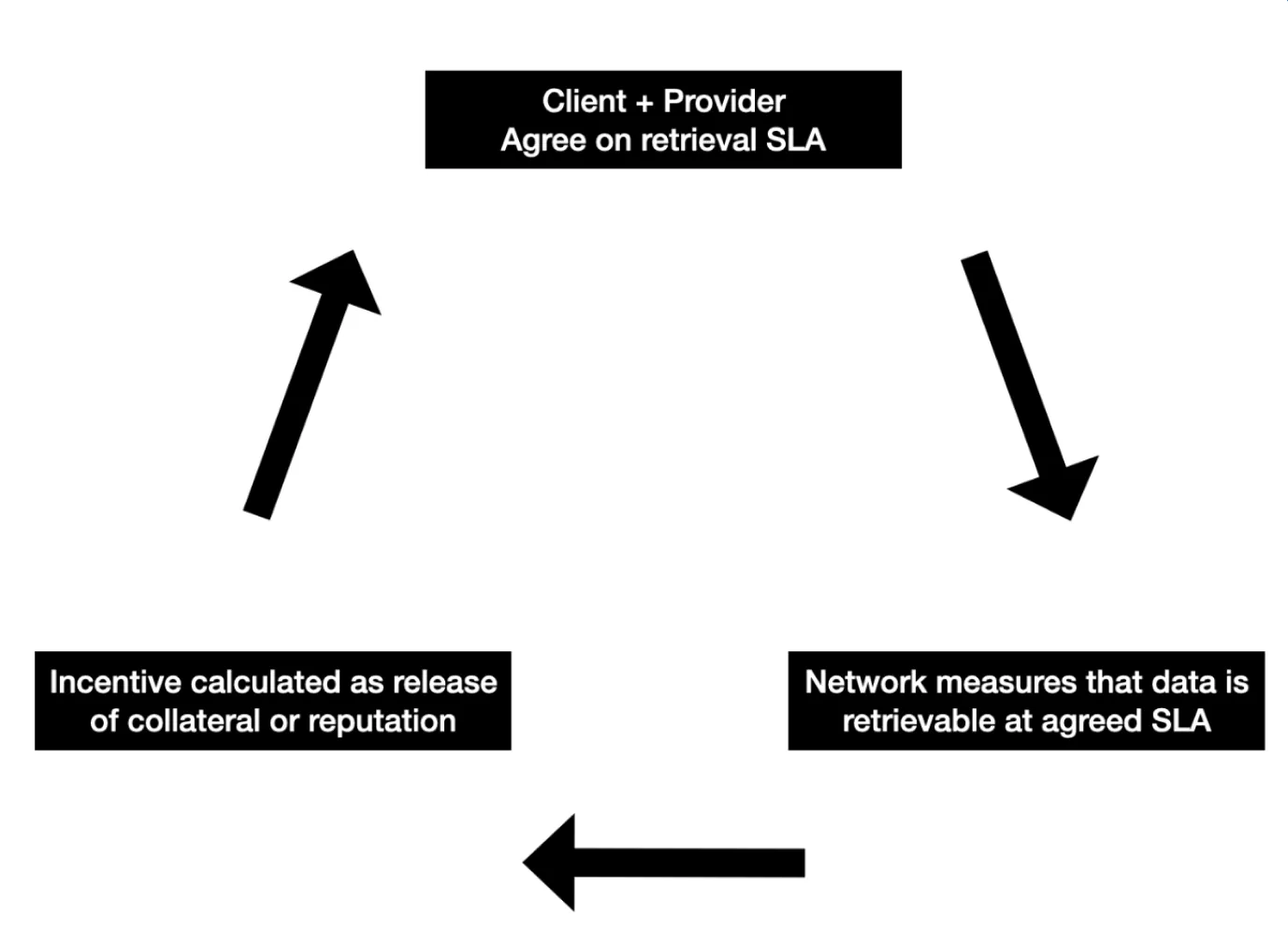
The Reputation WG
One of the most developed portions of the Filecoin ecosystem is the data onboarding incentives built through Filecoin Plus, which help attract new clients and encourage growth of Filecoin tooling and applications. Caro Cai presented updates from the SP Reputation Working Group including the status of Retrieval Bot, a tool that measures the retrieval rate of the network.
{{< youtube title="SP Reputation WG" id="https://www.youtube.com/watch?v=QP-AyYK86R8&list=PL_0VrY55uV1_YBBxt5rCooKSpSK4twObN&index=4" >}}
In the retrieval track, we had a series of discussions around how these mechanisms are already helping track and incentivize retrievals within Filecoin - a key requirement for many clients. This provided a useful baseline for how to progressively iterate on retrieval incentives, and helped establish interfaces to break down the overall retrieval problem into more manageable components. In his talk Fil+ for Retrieval Incentives, Deep Kapur did a great job outlining how the data programs team is testing retrieval incentives for open datasets.
{{< youtube id="https://www.youtube.com/watch?v=W95cX9Wsx1A&list=PL_0VrY55uV1_YBBxt5rCooKSpSK4twObN&index=6" title="Fil+ For Retrieval Incentives" >}}
Building on the themes of content retrieval and SP reputation, Miroslav Bajtoš presented SPARK, a decentralized network of permissionless nodes performing retrieval checks.
{{< youtube id="https://www.youtube.com/watch?v=6S4fR6wDL5w&list=PL_0VrY55uV1_YBBxt5rCooKSpSK4twObN&index=5" title="Sparking Content Retrievability " >}}
Overall, better metrics collection and sampling are needed to increase the reliability and granularity of retrieval data, and improve incentive feedback loops.
The markets & data layer on Filecoin
Interface vs Internals
There was a healthy technical discussion in Iceland about what parts of the Filecoin data model should be part of an interface contract to users, and which parts reflect internals of the current system that should be abstracted in order to allow change. One important evolution in progress is FRC 69, defining an evolution of Piece CIDs in order to more precisely define stored data.
A point that remains a core area of debate is the role of IPLD in the filecoin data layer. Today, most data onboarded to Filecoin is stored as CAR archives, which forces an abstract framing layer on top of data as a future-proofing mechanism. Other approaches like comm-pact were proposed to reduce complexities in the current interface, which spurred an active discussion about the tradeoffs at this layer.
Watch: User Data + Data Structures, CommPact, Filecoin and Content Addressing
Driving demand
The largest driver in the continued development of the Filecoin retrieval layer is client demand. The retrievability properties of data are a large factor in the overall price of storage. Today, a client’s specific retrieval requirements are negotiated with storage providers, and this leads to clear efficiencies both in automating those negotiations, providing stronger guarantees to both parties, and allowing automatic processes like data DAOs to also engage in the market.
In Iceland, discussions around current client tooling, including Saturn, Motion, and Singularity continued to refine how those clients currently structure their filecoin retrievals, and identified leverage points where client changes can align incentives for better, faster retrievals.
Watch: Saturn and SPs, Motion and SPs, Singularity V2
Takeaways
- We’re quickly approaching FIP consensus on defining retrievability.
- Filecoin can better match the underlying costs of retrieval in its incentivization.
- There are opportunities to use the governance structure within the Filecoin ecosystem to track and incentivize retrievals.
- An important ongoing workstream is the evolution of Piece CIDs to more precisely define stored data.